Retryable注解
🌈特别说明
通过HelloWorld这个最简单的案例,我们可以看到Retryable注解就是SnailJob中最重要的入口,那么接下来我们就要看一下这个注解中定义了哪些属性, 又给了我们哪些可以配置的选项呢?
源码地址: snail-job-demo
Retryable注解全貌
| 参数 | 描述 | 默认值 | 必须指定 |
|---|---|---|---|
| scene | 场景 | 无 | ✅ |
| include | 包含的异常 | 无 | ❌ |
| exclude | 排除的异常 | 无 | ❌ |
| retryStrategy | 重试策略 | LOCAL_REMOTE | ✅ |
| retryMethod | 重试处理入口 | RetryAnnotationMethod | ✅ |
| idempotentId | 幂等id生成器 | SimpleIdempotentIdGenerate | ✅ |
| retryCompleteCallback | 服务端重试完成(重试成功、重试到达最大次数)回调客户端 | SimpleRetryCompleteCallback | ❌ |
| isThrowException | 本地重试完成后是否抛出异常 | true | ❌ |
| bizNo | 标识具有业务特点的值比如订单号、物流编号等,可以根据具体的业务场景生成,具体的生产规则参考:Spi扩展点 | 无 | ❌ |
| localTimes | 本地重试次数 次数必须大于等于1 | 3 | ✅ |
| localInterval | 本地重试间隔时间(s) | 2 | ✅ |
| timeout | 同步(async:false)上报数据需要配置超时时间 | 60 * 1000 | ❌ |
| unit | 超时时间单位 | TimeUnit.MILLISECONDS | ❌ |
| forceReport | 是否强制上报数据到服务端 | false | ❌ |
| async | 是否异步上报数据到服务端 | true | ❌ |
| propagation | REQUIRED: 当设置为REQUIRED时,如果当前重试存在,就加入到当前重试中,即外部入口触发重试 如果当前重试不存在,就创建一个新的重试任务。 REQUIRES_NEW:当设置为REQUIRES_NEW时, 无论当前重试任务是否存在,都会一个新的重试任务。 | REQUIRED | ✅ |
可以看到我们能够自定义的参数还是很多的,那么接下来我将用分组的形式来跟大家讲解这些参数。
基础设置参数
| 参数 | 描述 | 默认值 | 必须指定 |
|---|---|---|---|
| scene | 场景 | 无 | ✅ |
| localTimes | 本地重试次数 次数必须大于等于1 | 3 | ✅ |
| localInterval | 本地重试间隔时间(s) | 2 | ✅ |
为什么叫基础设置参数呢?因为这是几乎每个重试组件都会实现的功能,也是我们在使用一款重试组件时最需要的配置。
scene 既是场景ID,我们先来了解一下SnailJob中两个最基本的概念——组和场景
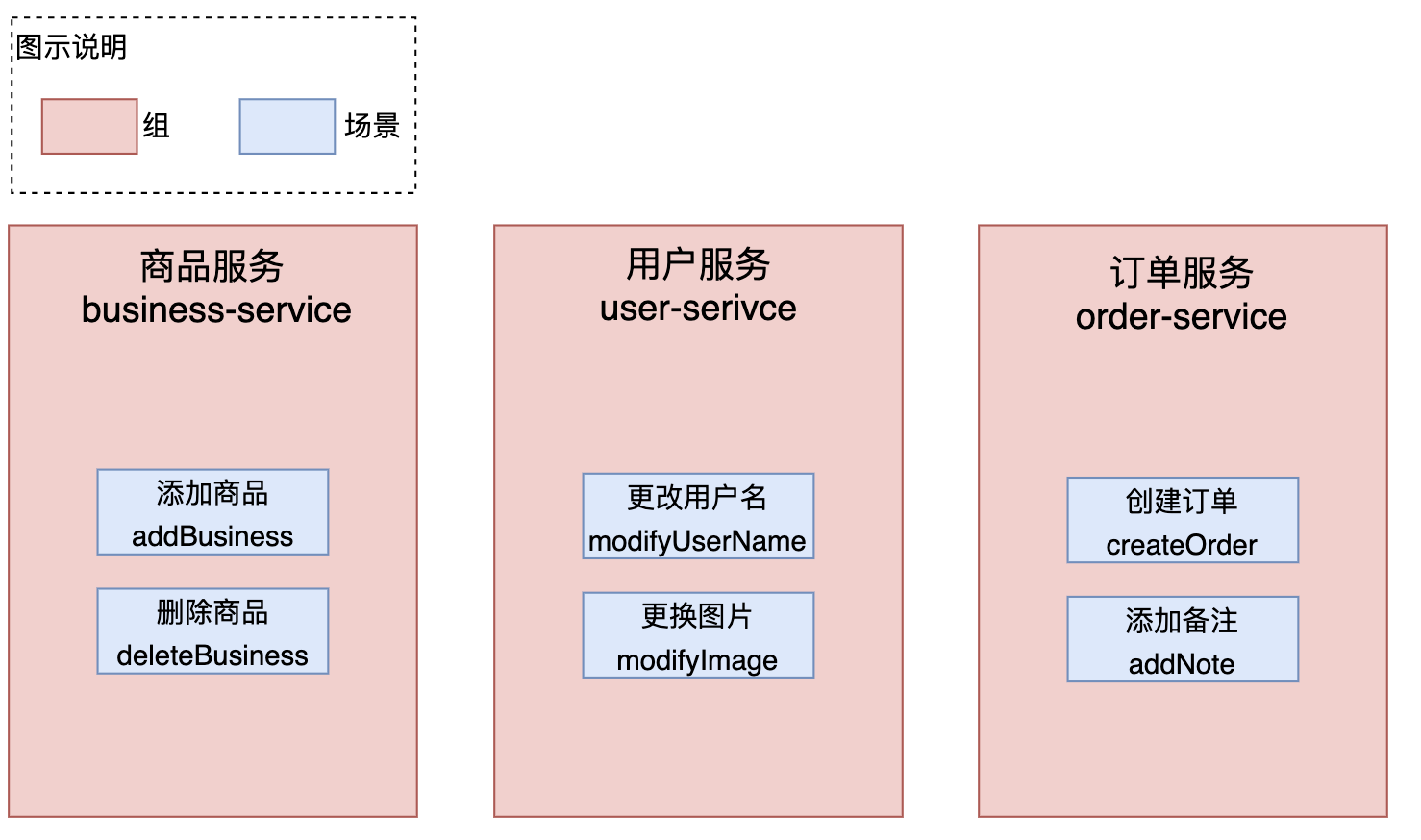
我们以电商系统为例,比如说这个系统中存在着商品服务,用户服务和订单服务。那么每个服务,其实就是一个组,而每个服务中都有若干个接口,这些实现功能的接口对应的就是SnailJob中的场景。 在Retryable注解中,场景值是唯一必须要手动指定且没有默认值的参数,这也就是为什么我们在第一个案例中仅仅指定了scene参数的值后就可以开始上手使用SnailJob了。 ⚠️ 注意,scene值一旦指定后不要修改,否则会使历史重试数据失效。
localTimes,指的是我们在本地重试的次数,默认是在本地重试三次,在使用中我们可以根据具体的场景,来指定重试的次数。
localInterval指的是本地重试的间隔时间,指的是系统在进行两次重试时的间隔
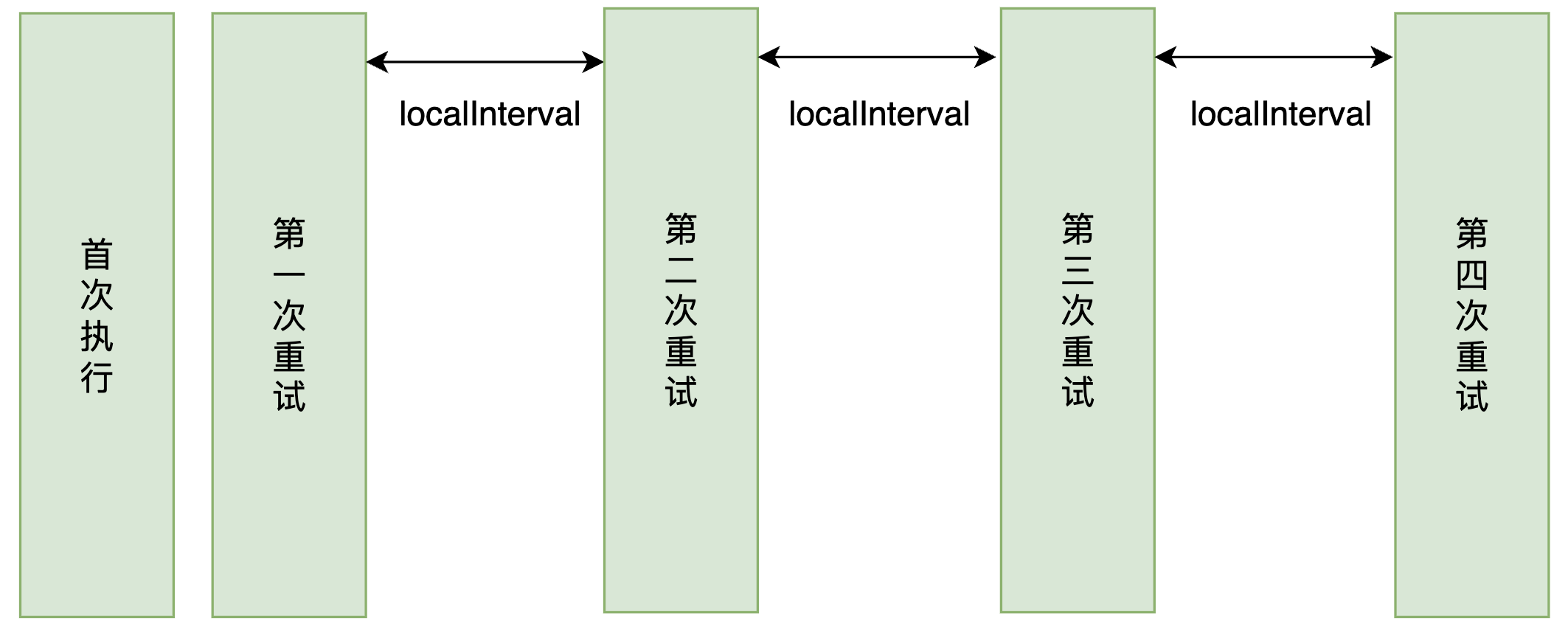
那么讲解完成这些参数之后我们来一个案例测试
// 这个函数里面我们设置重试次数为4,每次间隔10s
@Retryable(scene = "localRetryWithBasicParams",localTimes = 4,localInterval = 10)
public void localRetryWithBasicParams(){
System.out.println("local retry 方法开始执行");
double i = 1 / 0;
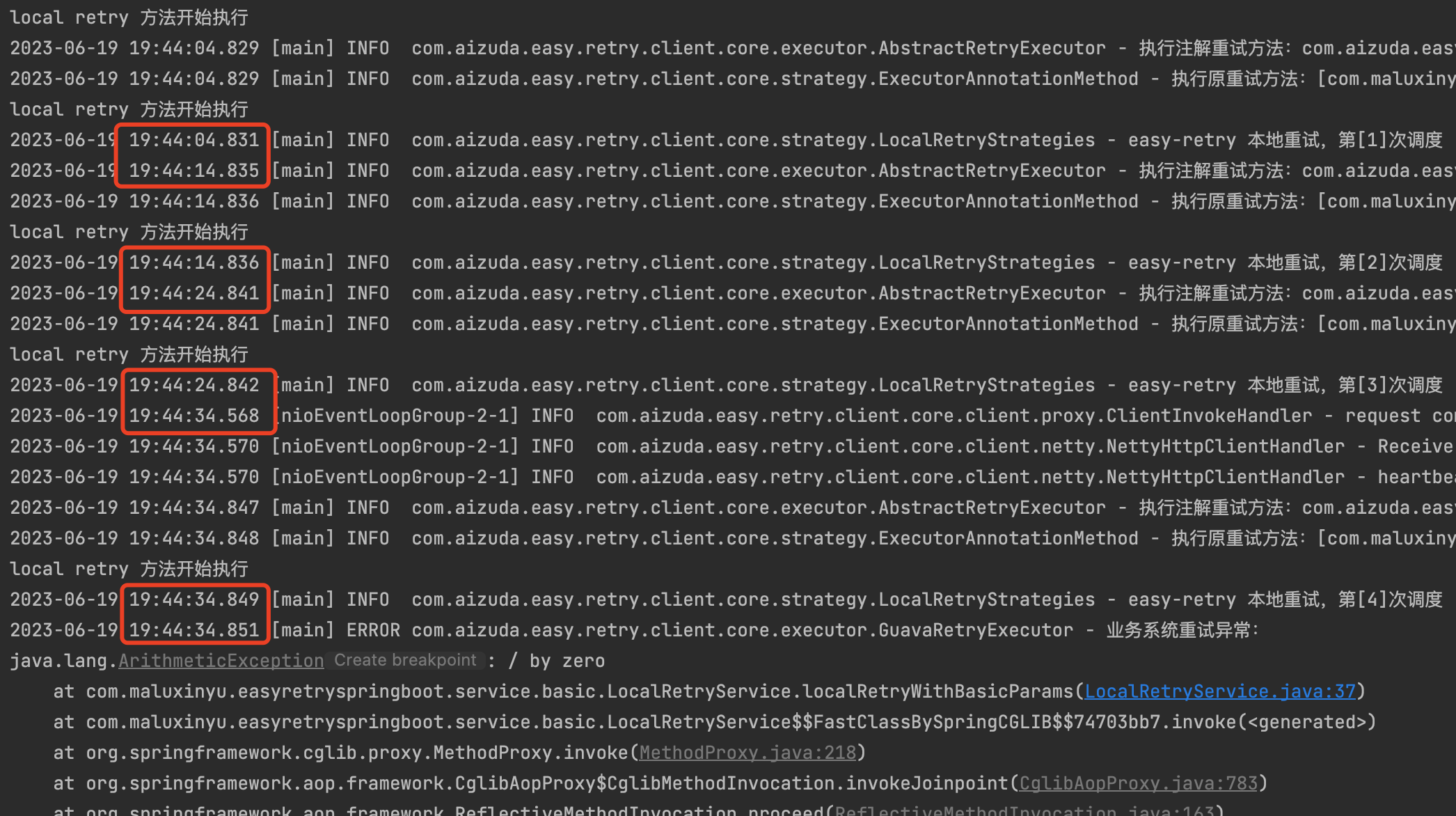
}我们通过控制台观察输出结果,可以看到,共计打印了5次 "local retry 方法开始执行"语句,且每次调度之间间隔为10s。
异常相关参数
| 参数 | 描述 | 默认值 | 必须指定 |
|---|---|---|---|
| include | 包含的异常 | 无 | ❌ |
| exclude | 排除的异常 | 无 | ❌ |
| isThrowException | 本地重试完成后是否抛出异常 | true | ❌ |
接下来我们来讲解和异常相关的参数,重试动作大多是发生在程序遭遇异常的场景中。因此对于异常的处理也是重试动作中的一个重要部分。
include参数代表包含的异常,什么意思呢?就是我们指定当遭遇到指定的异常时,才进行重试动作。
exclude参数和include参数是相反的,如果我们在exclude中指定了相关异常,那么遇到对应异常时则不会发生重试动作。
isThrowException这个参数就比较简单了,代表我们进行完成本地重试后是否需要抛出异常,默认是会抛出这个异常,如果我们在这个选项中选择了false,这不会再将原始的异常抛出。
接下来我们来测试一下这些异常参数,我们首先在项目里面定义两个异常类BusinessException和ParamException,其中ParamException是BusinessException的子类
// 定义一个统一的业务异常类
public class BusinessException extends RuntimeException{
public BusinessException(String message) {
super(message);
}
}// 定义一个参数异常处理类,是业务异常类的子类
public class ParamException extends BusinessException{
public ParamException(String message) {
super(message);
}
}我们首先抛出一个非指定的异常,观察下是否会发生重试,这个案例中我们依然抛出一个ArithmeticException异常,但是我们只指定当遇到ParamException异常时才会进行重试。
@Retryable(scene = "localRetryIncludeException",include = ParamException.class)
public void localRetryIncludeException(){
System.out.println("local retry include exception 方法开始执行");
double i = 1 / 0;
}运行后观察控制台我们可以看到,仅执行了一次,并未进行重试

接下来我们抛出指定异常,例如抛出自定义的ParamException异常,观察是否会重试。
@Retryable(scene = "localRetryIncludeException",include = ParamException.class)
public void localRetryIncludeException(){
System.out.println("local retry include exception 方法开始执行");
throw new ParamException("此处发生了指定异常Param Exception");
}运行方法后我们观察控制台,看到方法发生了重试。
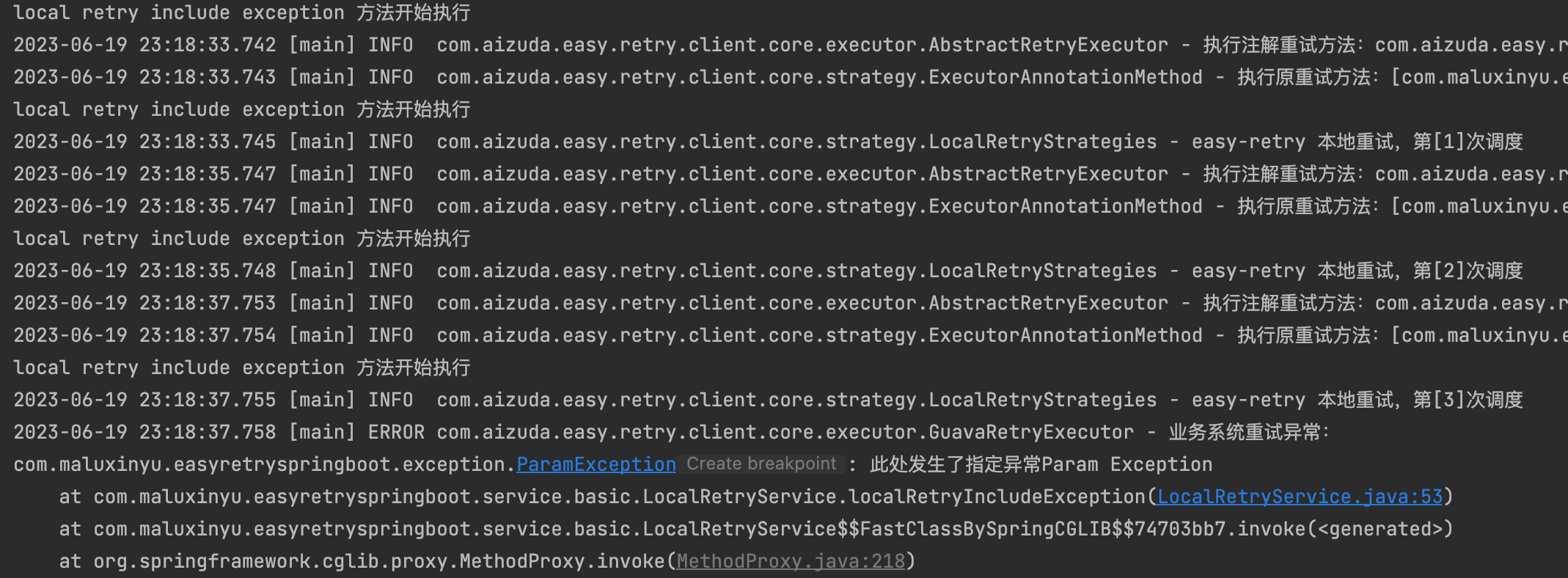
当然,由于ParamException是BusinessException的子类,当我们指定处理的类是父类BusinessException时,同样也会进行重试。这样子我们就可以通过自定义异常来指定某些特定报错的业务场景才执行重试逻辑,同时如果也可以通过指定异常的继承关系对一类异常场景进行统一的处理。
@Retryable(scene = "localRetryIncludeException",include = BusinessException.class)
public void localRetryIncludeException(){
System.out.println("local retry include exception 方法开始执行");
throw new ParamException("此处发生了指定异常Param Exception");
// throw new NullPointerException();
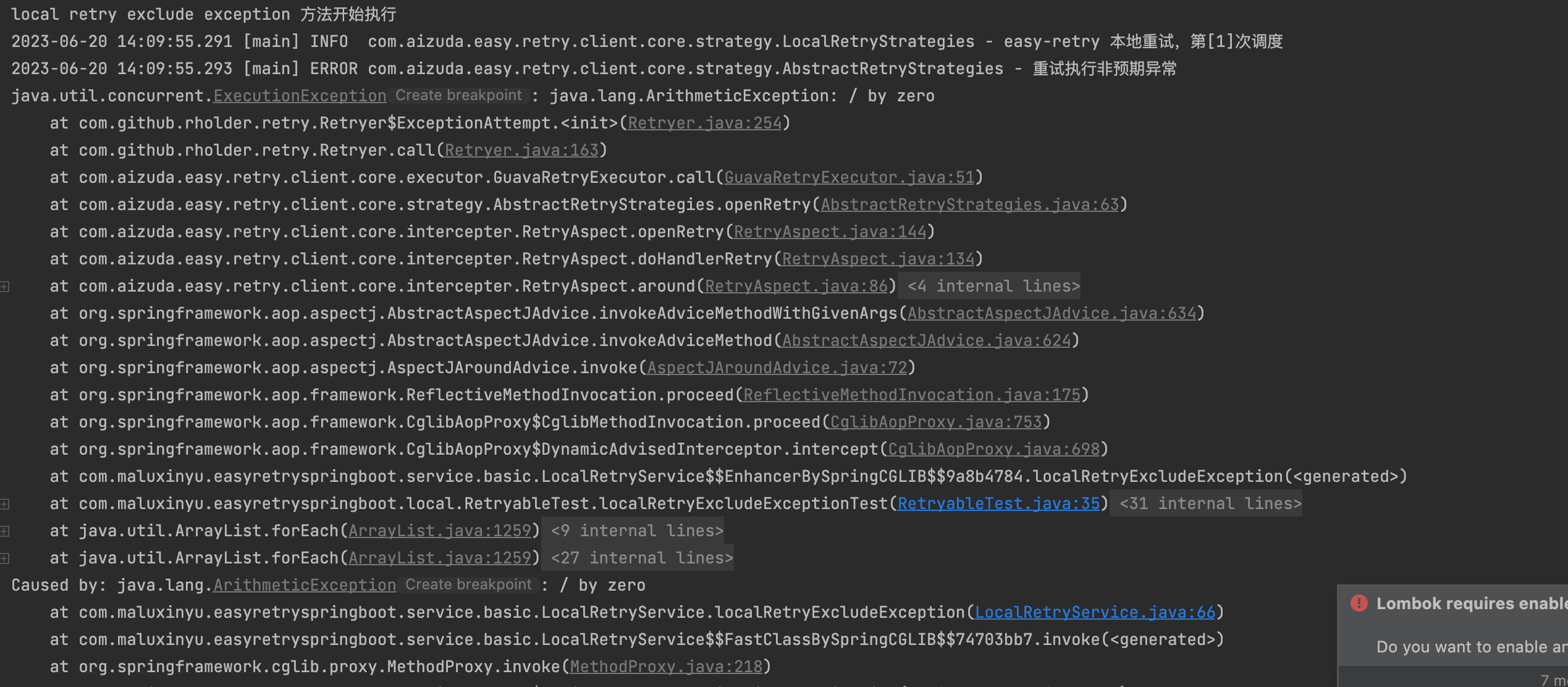
}接下来我们看exclude参数,这个参数和include是相反的,include是遇到指定的异常就重试,而exclude是遇到指定的异常就不重试。 我们直接给出案例
@Retryable(scene = "localRetryExcludeException",exclude = {ParamException.class,ArithmeticException.class})
public void localRetryExcludeException(){
System.out.println("local retry exclude exception 方法开始执行");
double i = 1 / 0;
throw new ParamException("此处发生了参数异常");
}观察控制台输出,我们可以看到没有进行重试就抛出了对应的异常
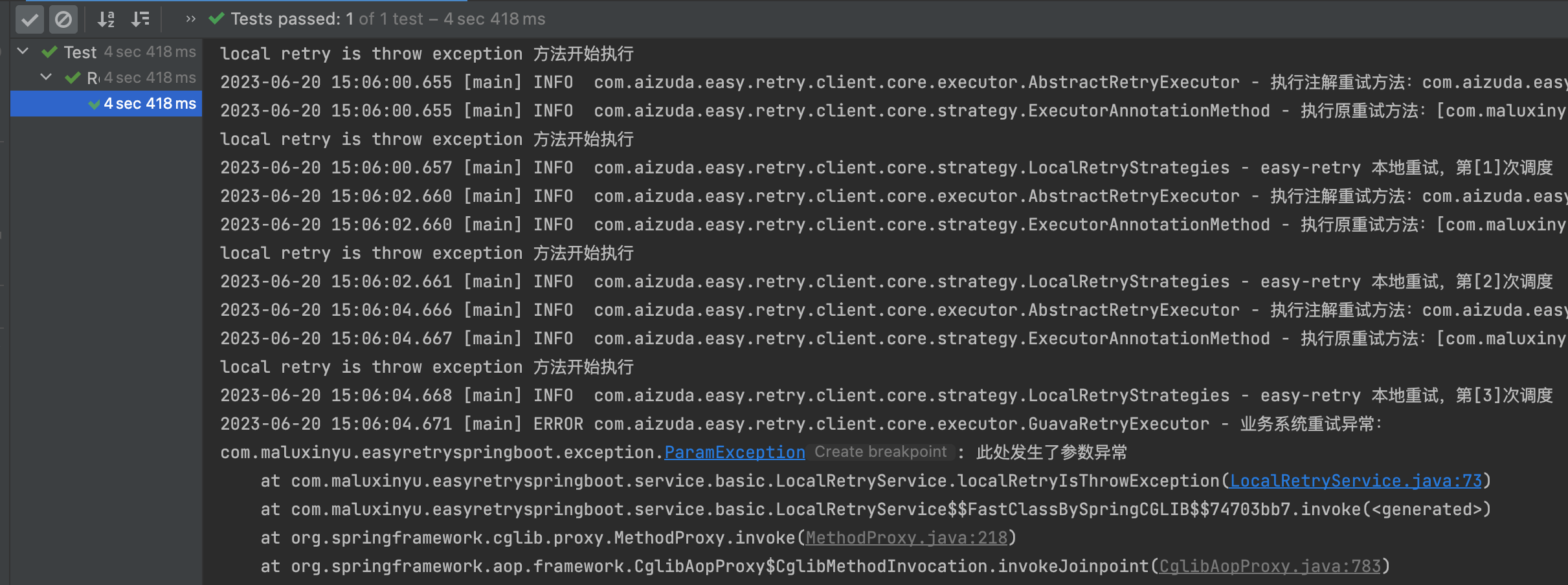
接下来我们讲解isThrowException参数,这个参数比较简单,表示我们在进行重试动作后是否会将异常抛出来,我们给出一个案例,在这个案例中我们继续在上一个exclude参数中一个未测试到的场景,此时我们指定exclude的参数为ArithmeticException,然后再指定isThrowException的值为false。
@Retryable(scene = "localRetryIsThrowException",exclude = ArithmeticException.class,isThrowException = false)
public void localRetryIsThrowException(){
System.out.println("local retry is throw exception 方法开始执行");
throw new ParamException("此处发生了参数异常");
}此时我们观察服务台输出,可以看到由于指定的异常,并不在我们抛出异常的列表中。因此发生了重试,大家可以看到异常的信息,依然是打印出来的,但是在此处,整个测试案例就是通过了的。这也就意味着上游调用这个接口的服务方并不会感知到本次异常的发生。 因此,isThrowException参数会屏蔽本次异常的发生,而不是向上抛出异常。
服务端上报相关参数
| 参数 | 描述 | 默认值 | 必须指定 |
|---|---|---|---|
| retryStrategy | 重试策略 | LOCAL_REMOTE | ✅ |
| async | 是否异步上报数据到服务端 | true | ❌ |
| timeout | 同步(async:false)上报数据需要配置超时时间 | 60 * 1000 | ❌ |
| unit | 超时时间单位 | TimeUnit.MILLISECONDS | ❌ |
在上述的参数案例中,我们主要讲解了SnailJob在本地重试中的参数配置,而SnailJob同样可以支持管理后台可视化查看重试行为。接下来我们来讲解SnailJob的客户端是如何连接到服务端的,以及服务端都支持哪些可配置的参数。
retryStrategy参数代表了我们需要指定的重试策略,这个重试策略目前支持三种,参数的默认值是本地重试。这是SnailJob中非常重要的一个概念,三种模式的释义大家可以参数表格
| 策略 | 释义 |
|---|---|
| ONLY_LOCAL | |
| 本地重试 | 在内存中执行重试动作,如果重试结束后依然异常则抛出异常或是打印错误日志 |
| ONLY_REMOTE | |
| 远程重试 | 将异常上报至服务端,由服务端管理重试的动作或是根据服务端的配置进行重试的动作 |
| LOCAL_REMOTE | |
| 先本地重试,再远程重试 | 优先在本地基于内存中完成重试动作,如果重试之后依然返回异常结果则将结果上报至服务端 |
在这个地方我们通过图示的方式来讲解一下三种模式具体的区别是什么:
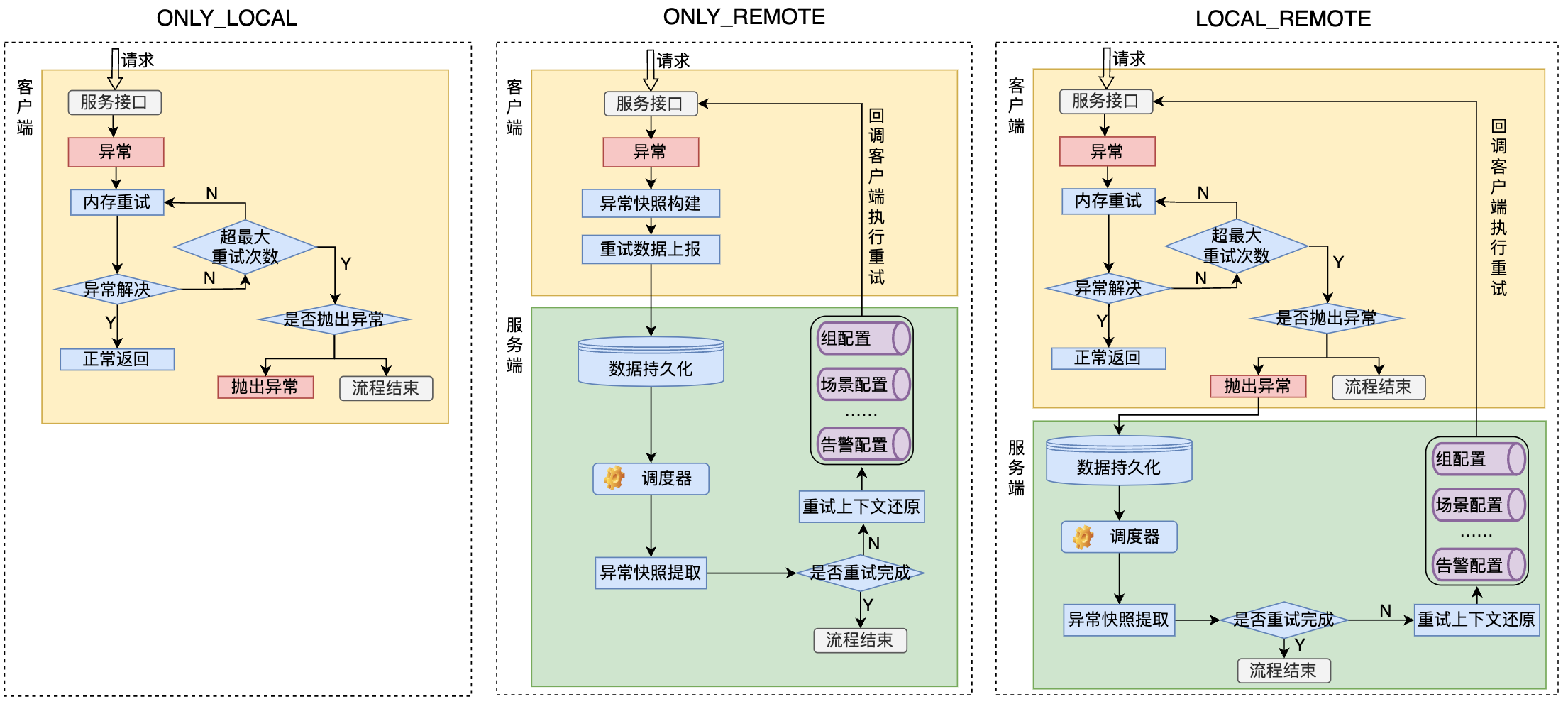
可以看到本地重试模式中仅仅是使用内存来完成重试,不涉及到和服务端的交互。 而远程重试模式则是在遭遇异常后构建异常快照,随后进行重试数据上报,上传重试数据到服务端,服务端进行数据持久化后再由调度器提取上报的异常快照,还原重试的上下文后回调客户端进行重试。 先本地重试,再远程重试模式顾名思义则是两者的结合,优先在本地进行重试,如果本地重试后依然返回异常结果,则进行数据上报,将未完成的异常数据上报至服务端,根据服务端指定的策略进行下一步的处理方案。
async参数代表是否异步上传数据到服务端,默认为true,当指定参数async为false时,请求将通过NettyClient进行实时数据上报,而默认状态下为异步上传,通过滑动窗口的方式进行异步数据上传。
timeout参数指当我们选择同步上报数据时请求的超时时间,默认为60 * 1000毫秒,即一分钟,unit参数和timeout参数是配套的,代表了我们同步上传数据超时时间的单位。
那么讲解完成这些参数后,我们通过案例来讲解一下这几个参数的具体使用方法吧。 由于后续的案例的都涉及到了客户端和服务端的交互,需要客户端也处于启动状态,所以后续的用例我们通过HTTP接口访问的形式来进行测试。 在使用远程重试相关的功能前,我们首先需要创建一个组,组名既是我们之前在SpringbootApplication中给出的@EnableEasyRetry注解指定的组名,在这个案例中组名为easy_retry_demo_group,因为需要我们手动指定相关的路由策略和Id生成模式。 Id生成模式指的是我们重试请求的唯一键,SnailJob中为我们指定了两种模式,分别是雪花算法模式和号段模式,大家可以根据业务场景自行选取。 指定分区的配置允许我们将不同的任务放置在不同的分区中进行管理,项目中自带的建表语句中为我们创建了表retry_task_0和retry_dead_letter_0,因此此处我们将指定分区的值设置为0,如果选择了其他的分区,那么我们需要在数据库中创建相关的表。
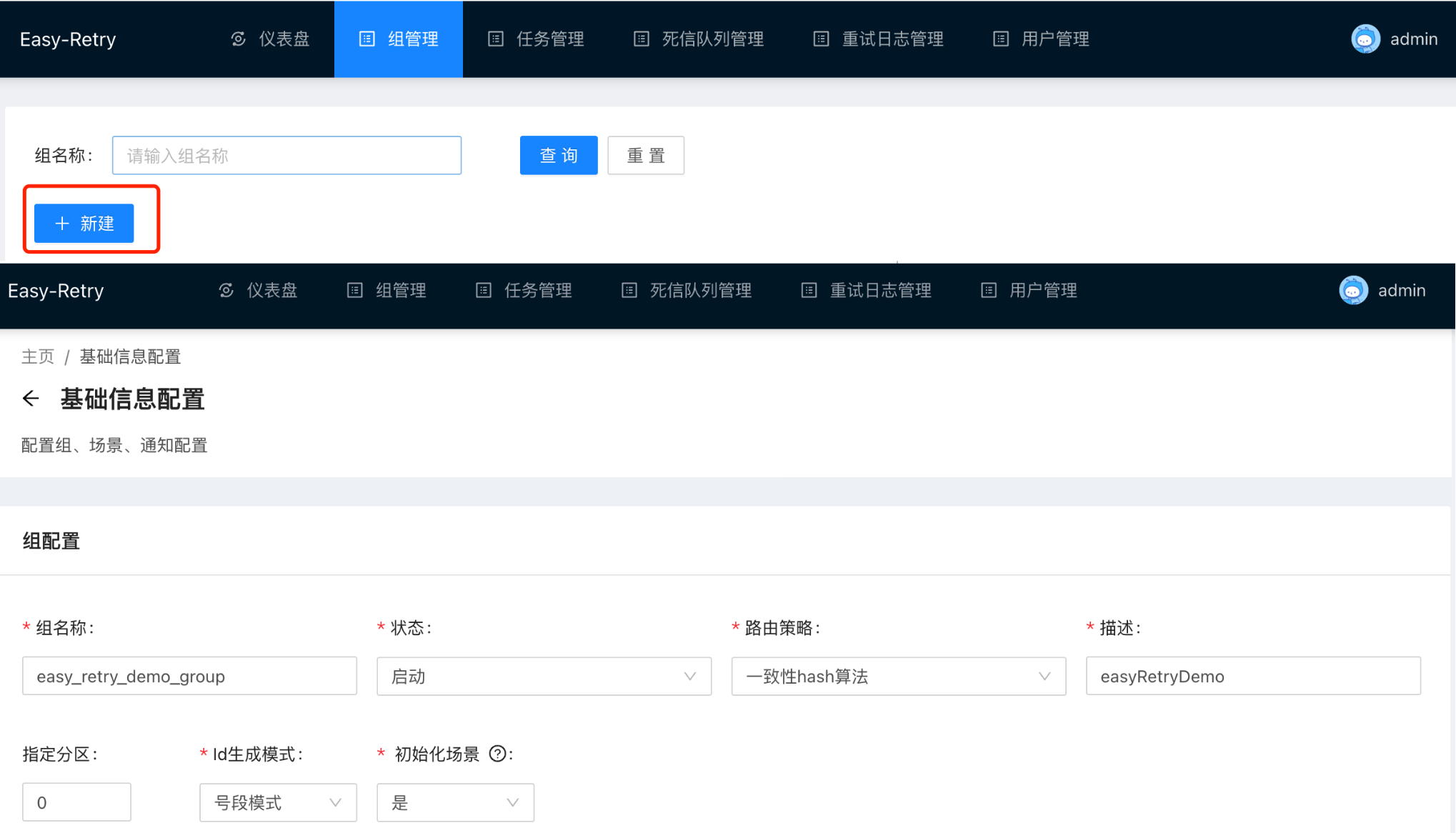
在创建完成相关组之后,写一个远程重试的方法。
@Component
public class RemoteRetryService {
@Retryable(scene = "remoteRetry",retryStrategy = RetryType.ONLY_REMOTE)
public void remoteRetry(){
System.out.println("远程重试方法启动");
double i = 1 / 0;
}
}然后在Controller层调用这个方法
@RestController
@RequestMapping("/remote")
public class RemoteRetryController {
@Autowired
private RemoteRetryService remoteRetryService;
@GetMapping("/retry")
public void remote(){
remoteRetryService.remoteRetry();
}
}启动客户端的服务,随后通过IDEA发起一个HTTP请求
此时可以看到我们的控制台已经可以看到本次执行的任务
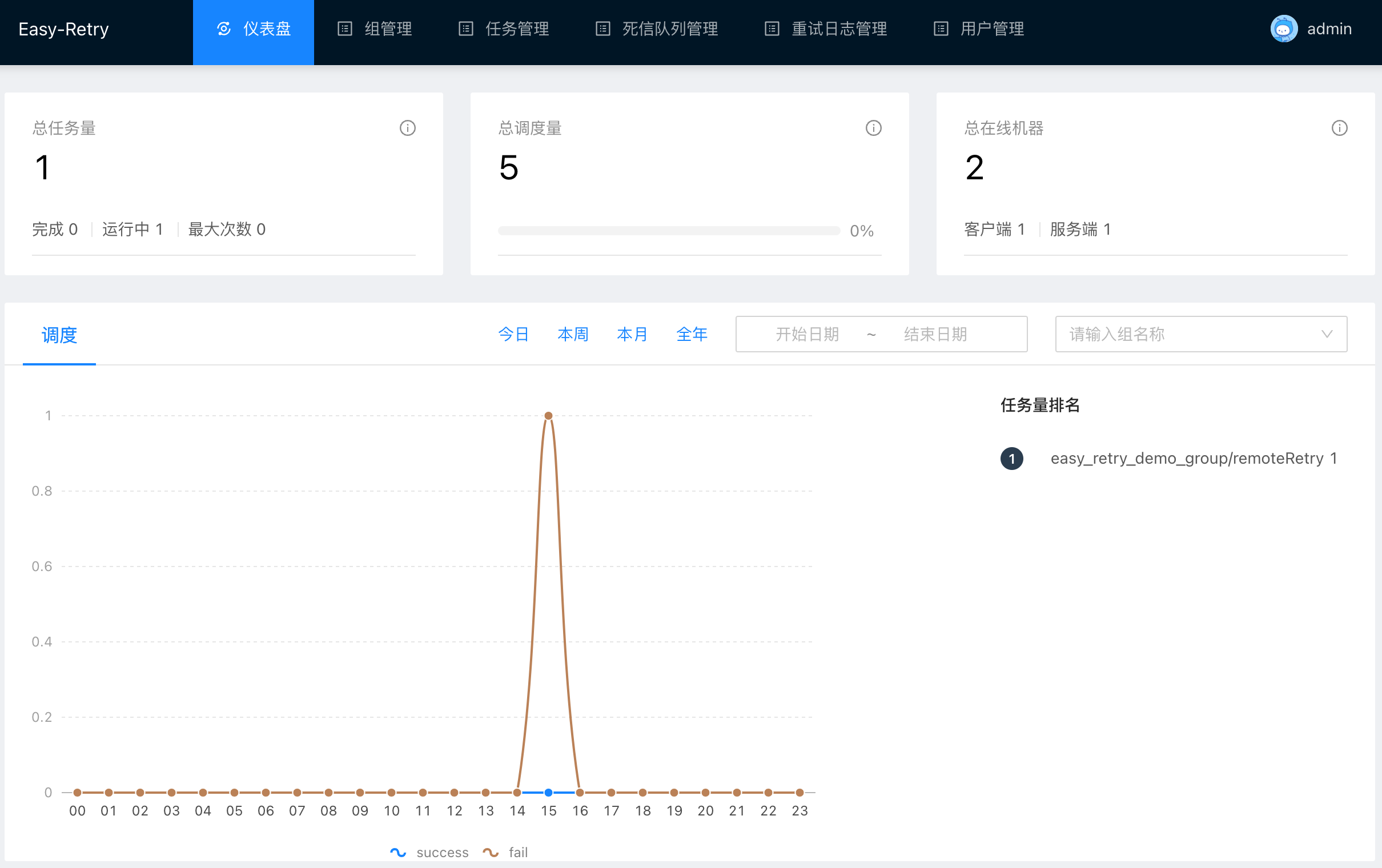
随后我们进入任务管理列表中查看请求的详情,可以看到已经产生了一条正在执行中的重试任务,目前的执行次数是8。
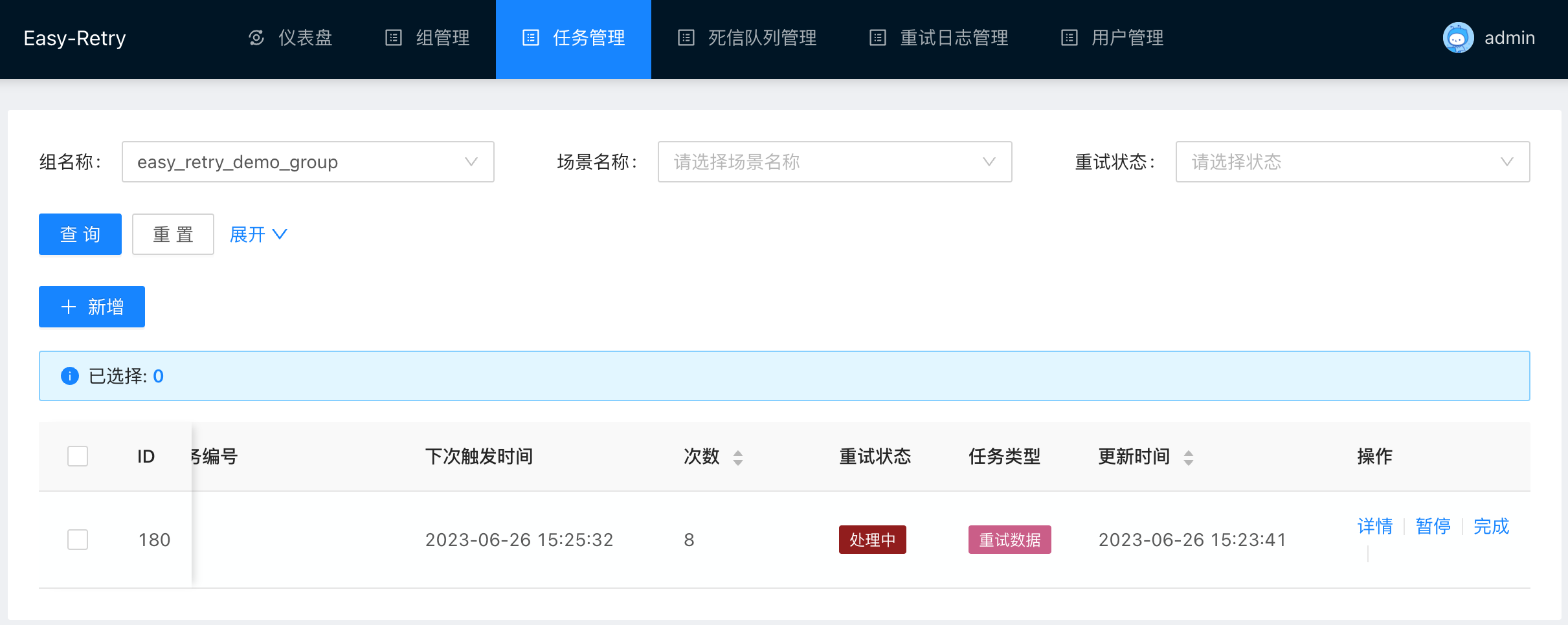
点击进入重试数据的详情,我们可以看到,本次请求的详细调度日志,由于在重试过程中还在持续发生异常,因此会不断地执行重试。
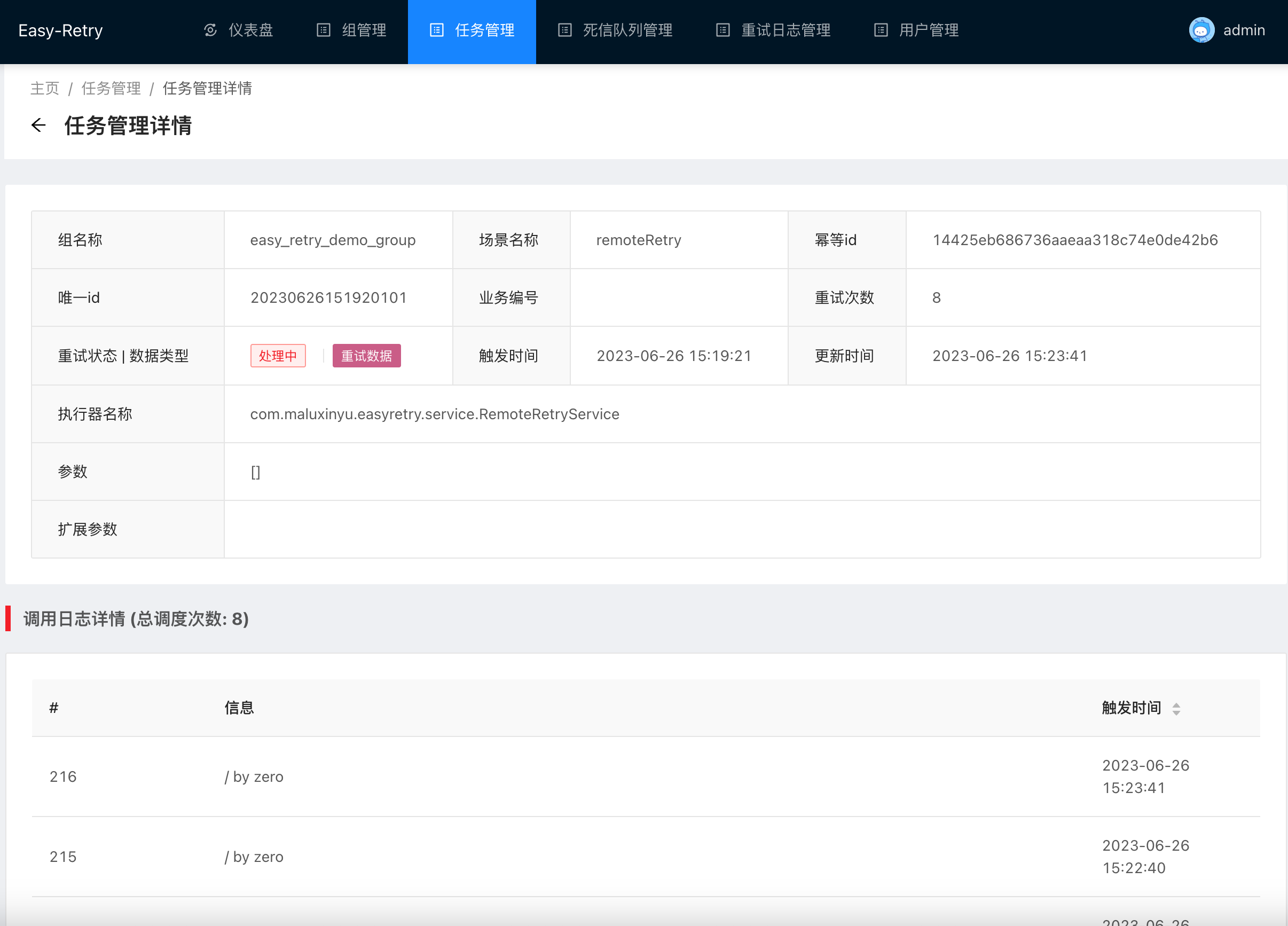
那么这个重试会有上限吗?当然会有,我们在组管理中找到对应的组,当我们启动服务的时候,会自动注册一个场景,此时场景初始化时最大的重试次数是21,调用链超时时间是6000毫秒。
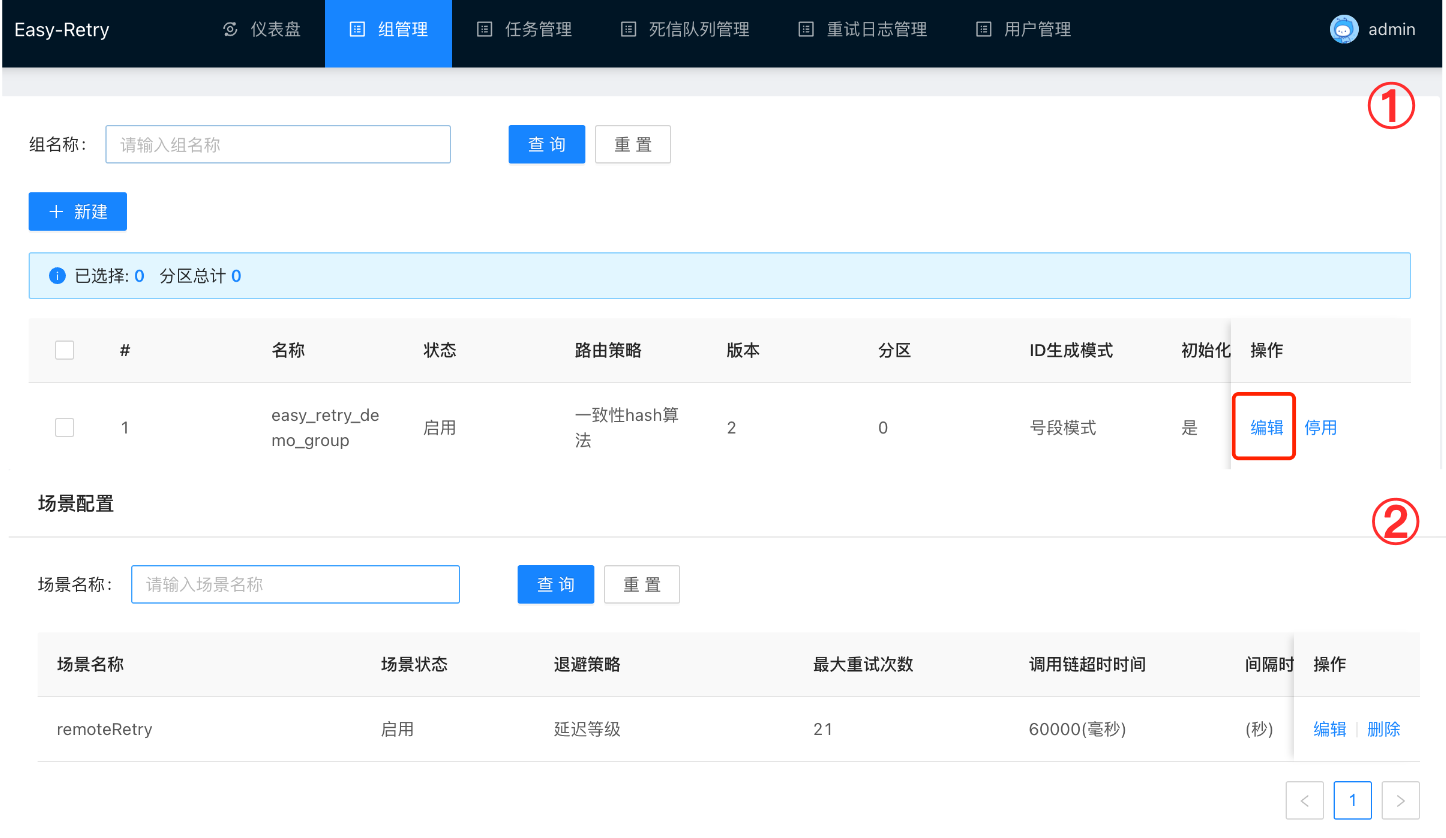
我们调低这个默认值,将最大重试次数调整到10次,看一下当超过最大重试次数时会发生什么。 可以看到,当重试数据达到最大次数时,此时会产生一条回调数据的任务。
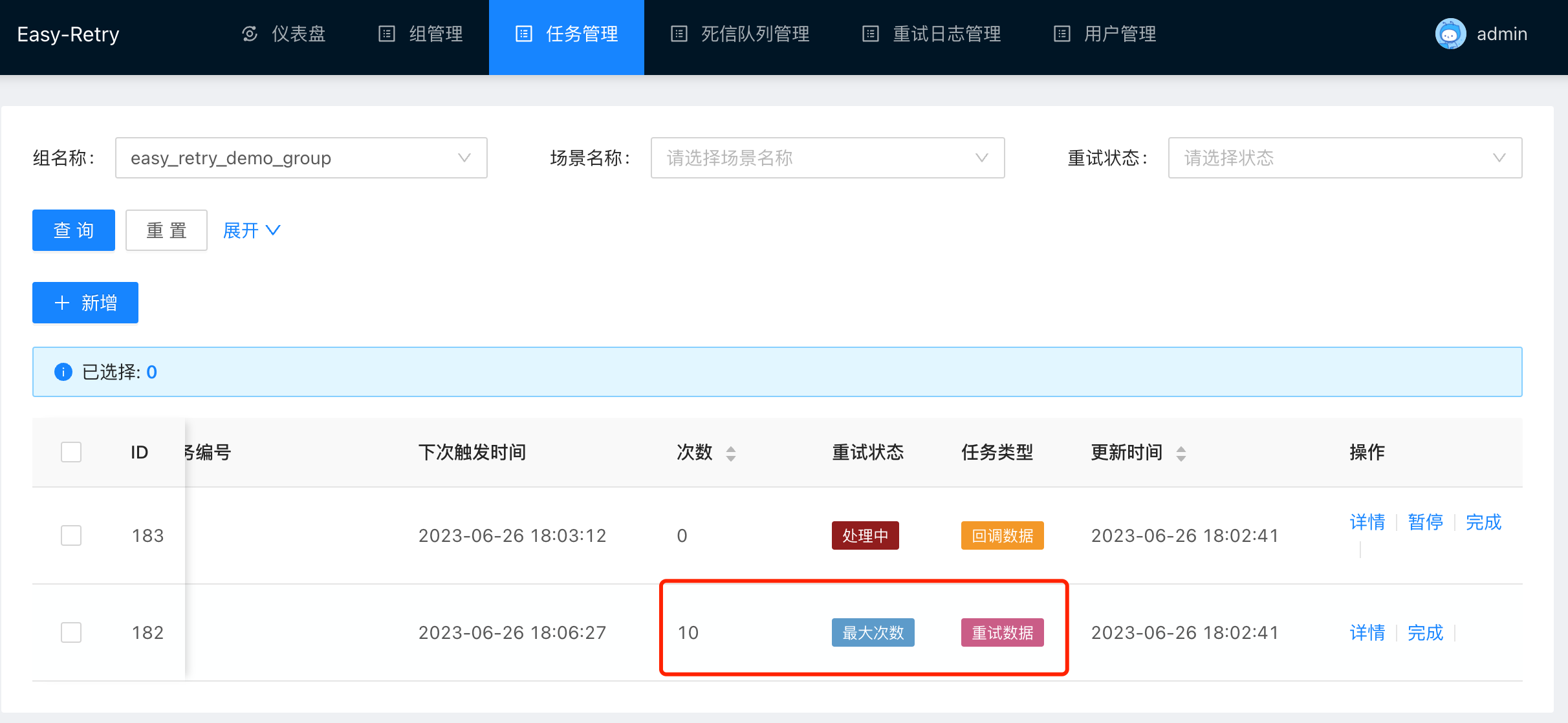
你可能会比较好奇为什么会产生两条任务?这就要从我们的交互流程来说起了,在远程重试的场景中,客户端遭遇异常后会进行重试的数据上报,服务端在接受到客户端的重试数据后会进行重试数据的持久化,随后会由调度器下发调度任务。此时会有两个执行器在等待,一个是重试执行器,一个是回调执行器,重试执行器的作用是触发任务调度,而回调执行器的作用则是将服务端调度的状态通知给客户端,客户端在接受到服务端的回调任务后可以执行自定义方法,来指定重试完成之后的后置动作,这部分内容在下面retryCompleteCallback中会详细介绍。
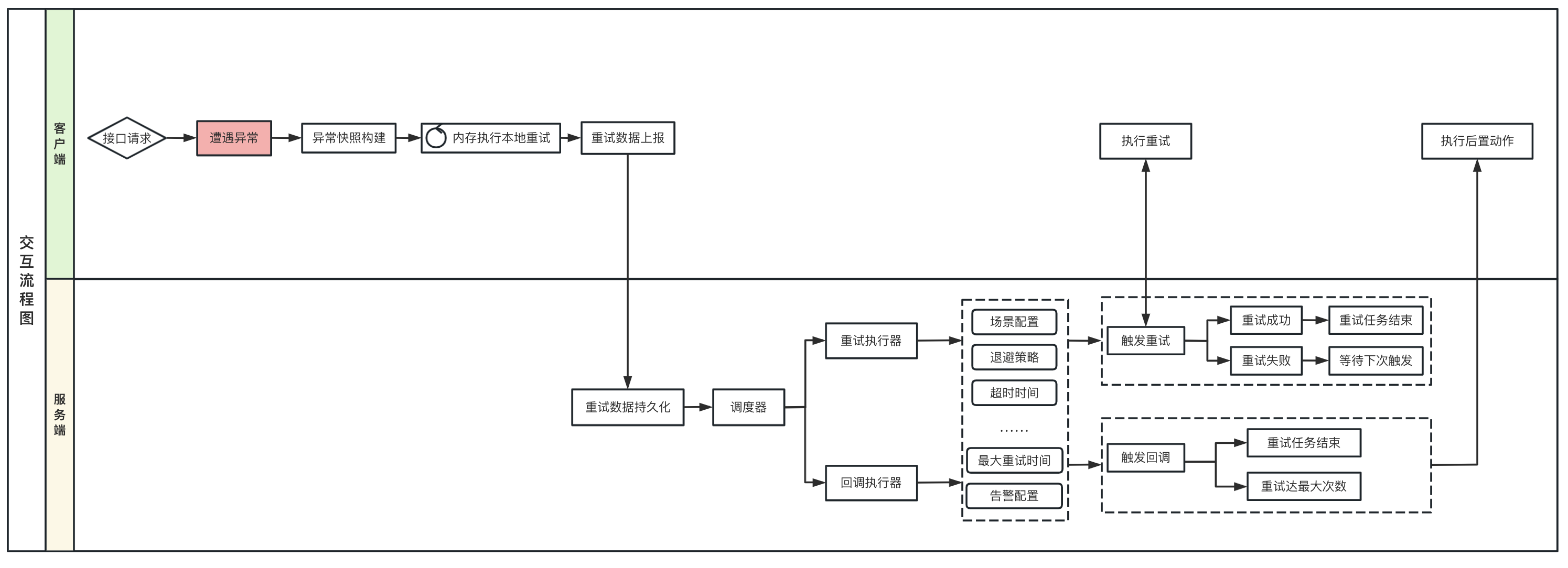
倘若重试任务超过最大重试次数后,将会从"任务管理"一栏中取消,加入到"死信队列管理"一栏中,此时我们认为这条任务是一条死信,不再进行重试执行。当然,如果在业务中因为下游的bug导致本任务的重试一直不成功,我们也可以点击死信队列管理中的回滚,将这条死信消息重新放入到"任务管理"Tab下面,再次执行重试任务。
接下来我们来用一个案例演示一下retryStrategy中的LOCAL_REMOTE、async、timeout、unit这四个参数,因为这几个参数都比较简单,因此我就放到一个案例中来进行处理了。首先我们定义一个同步上传的方法。
/**
* 使用先本地再远程的策略同步上传重试请求
* retryStrategy = LOCAL_REMOTE 代表本地重试3次后再执行远程上报
* async = false 代表使用同步上传的方式
* timeout = 1 代表超时时间为1
* unit = MINUTES 代表超时时间的单位是分钟
*/
@Retryable(scene = "remoteRetryWithSync",retryStrategy = RetryType.LOCAL_REMOTE,
async = false, timeout = 1, unit = TimeUnit.MINUTES)
public String remoteRetryWithLocalRemote(String requestId){
double i = 1 / 0;
return requestId;
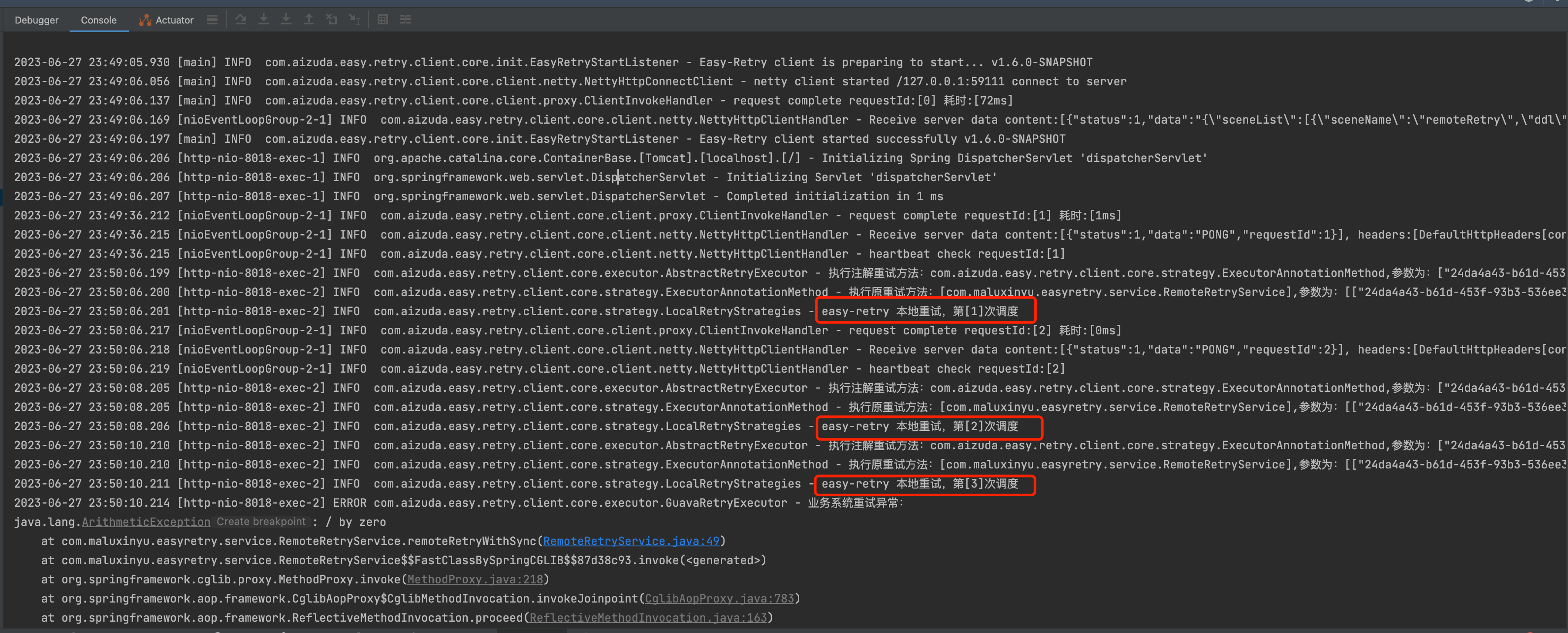
}观察结果我们可以看到,首先执行了三次本地重试,随后在本地抛出异常。
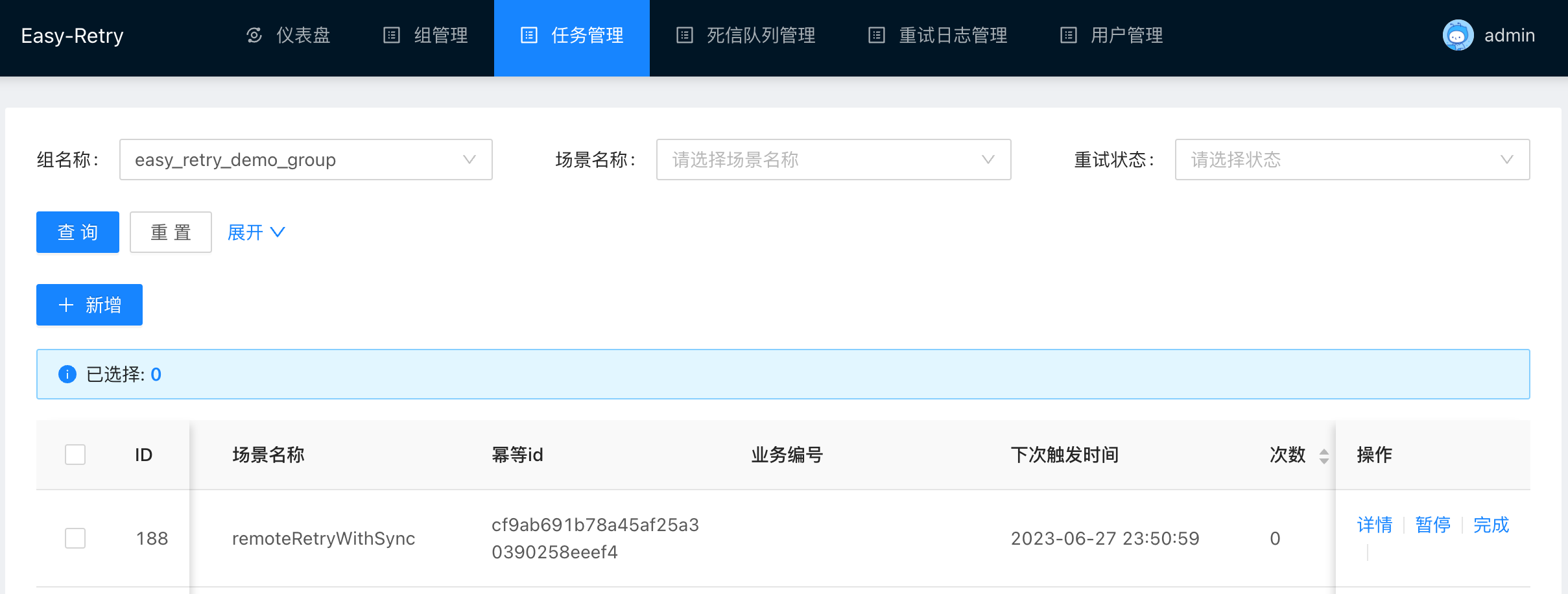
然后任务管理中出现了我们上报的任务。
业务相关参数
| 参数 | 描述 | 默认值 | 必须指定 |
|---|---|---|---|
| idempotentId | 幂等id生成器 | SimpleIdempotentIdGenerate | ✅ |
| retryMethod | 重试处理入口 | ExecutorAnnotationMethod | ✅ |
| retryCompleteCallback | 服务端重试完成(重试成功、重试到达最大次数)回调客户端 | SimpleRetryCompleteCallback | ❌ |
| bizNo | 标识具有业务特点的值比如订单号、物流编号等,可以根据具体的业务场景生成,生成规则采用Spel表达式解析。 | 无 | ❌ |
接下来的参数中主要是和我们业务相关的一些参数了,当我们在业务场景中使用SnailJob时,可以根据实际的业务需要来定制一些内容。首先我们对这些参数来做一个详细的介绍:
idempotentId 幂等Id生成器,每个重试请求中,其中默认的实现方法为SimpleIdempotentIdGenerate,我们一起来看一下这个方法是如何实现的。
public class SimpleIdempotentIdGenerate implements IdempotentIdGenerate {
@Override
public String idGenerate(IdempotentIdGenerateEntity idempotentIdGenerateEntity) throws Exception {
return SecureUtil.md5(idempotentIdGenerateEntity.toString());
}
}
/**
* 参数列表为IdempotentIdGenerateEntity包含了四个对象, 下面说明每一个下标代表的数据含义
* 场景名称: scene(String)
* 执行器名称: targetClassName(String)
* 参数列表: args(Object[])
* 执行的方法名称: methodName(String)
* scene, targetClassName, args, executorMethod.getName()
*
* @param t 参数列表
* @return idempotentId
* @throws Exception
*/
public interface IdempotentIdGenerate {
String idGenerate(IdempotentIdGenerateEntity idempotentIdGenerateEntity) throws Exception;
}可以看到,默认实现中我们取scene场景名称,targetClassName执行器名称,args参数列表,methodName执行的方法名称来进行了一个md5运算作为重试任务的幂等Id,由此来保证任务是唯一的,这种实现方式下,对象中的四个参数中有一个变化都会新建一个重试任务。 当然,在一些特殊的业务场景下我们可以重写IdempotentIdGenerate来实现幂等Id的自定义。 接下来我们再来看一个案例。这次我们来模拟一个业务场景,举个例子,一个商品下单的场景,用户购买某个限购的商品,此时用户可以通过手机下单,也可以通过PC下单,此时两个请求的订单号相同,一端下单成功后,另一端不可重复下单。此时假设下单服务发生异常,我们仅需产生一次重试任务即可,无需根据客户端不同发生多次请求。
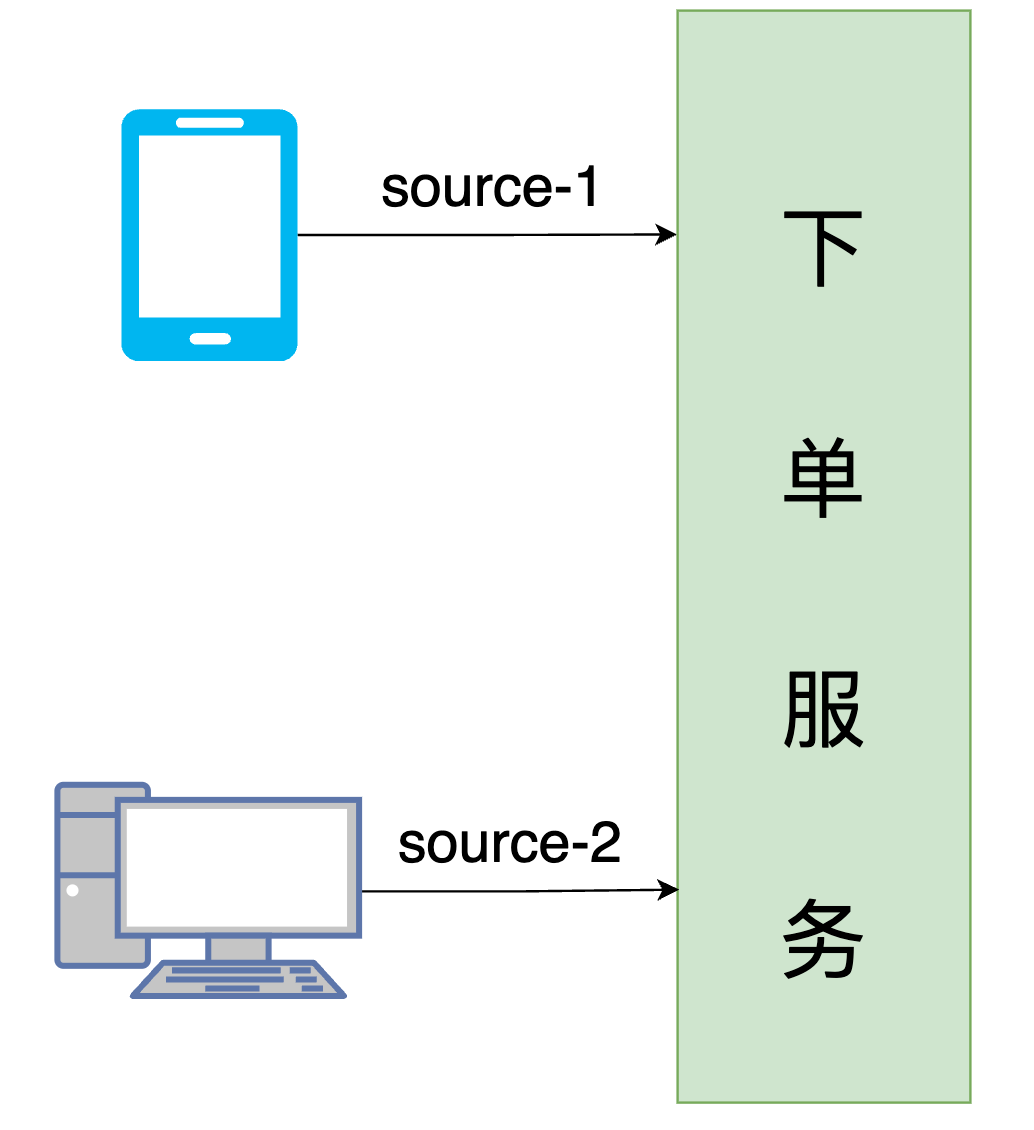
那么怎么来实现这个场景呢?我们首先来定义一个商品的VO,为了简化表述,我们在其中仅仅放入订单ID和订单来源信息两个字段。
@Data
public class OrderVo {
private String orderId; // 订单ID,用于唯一标识订单的编号
private Integer source; // 订单来源信息,1-手机端下单 2-PC端下单
}然后我们自定义一个幂等Id生成类
/**
* 使用自定义的幂等Id生成类 OrderIdempotentIdGenerate
*/
@Retryable(scene = "remoteRetryWithIdempotentId",retryStrategy = RetryType.ONLY_REMOTE,
idempotentId = OrderIdempotentIdGenerate.class)
public boolean remoteRetryWithIdempotentId(OrderVo orderVo){
double i = 1 / 0;
return true;
}在其中我们指定了幂等Id的生成规则为自定义的生成规则,然后我们在代码中继承IdempotentIdGenerate类,给出一个OrderIdempotentIdGenerate类,我们从IdempotentIdContext取出args参数,这个参数代表了我们从接口传入的参数,在这个接口中,我们取出args参数数组中下标为0的参数,转换为OrderVo类型,然后指定幂等Id的生成规则是取出orderId求md5。
public class OrderIdempotentIdGenerate implements IdempotentIdGenerate {
@Override
public String idGenerate(IdempotentIdContext idempotentIdContext) throws Exception {
Object[] args = idempotentIdContext.getArgs();
OrderVo orderVo = (OrderVo) args[0];
return SecureUtil.md5(orderVo.getOrderId());
}
}接下来我们测试看看效果吧。首先我们给出三个Post请求,其中请求1是原始请求,请求2中orderId和请求1一致仅仅修改source,请求3中source保持不变,仅仅修改orderId。
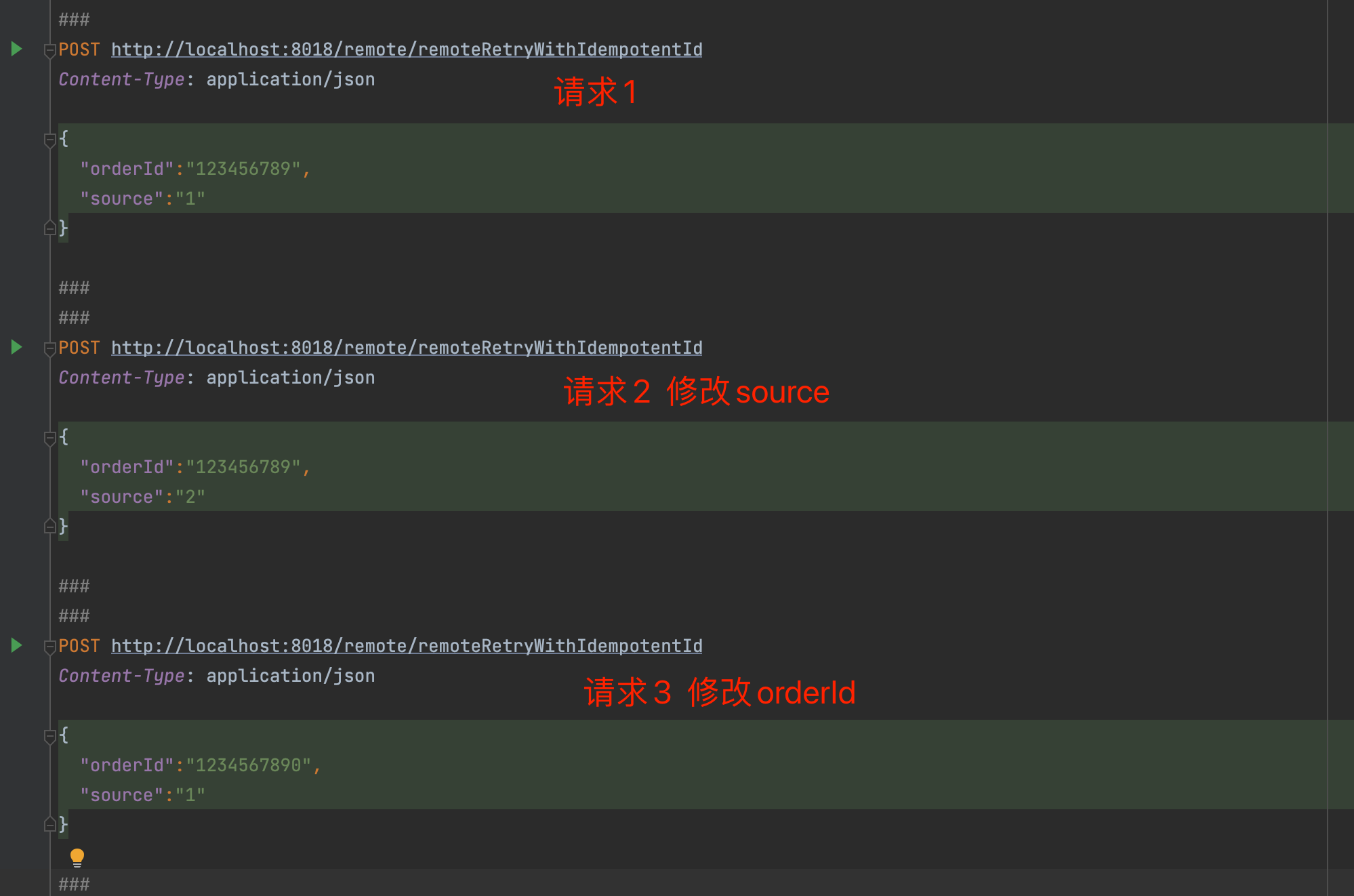
依次执行三个请求我们可以观察到,请求1和请求2执行之后仅有一条数据生成,幂等Id没有变化,也没有生成新的重试任务;而执行请求3之后生成了一条新的重试任务。
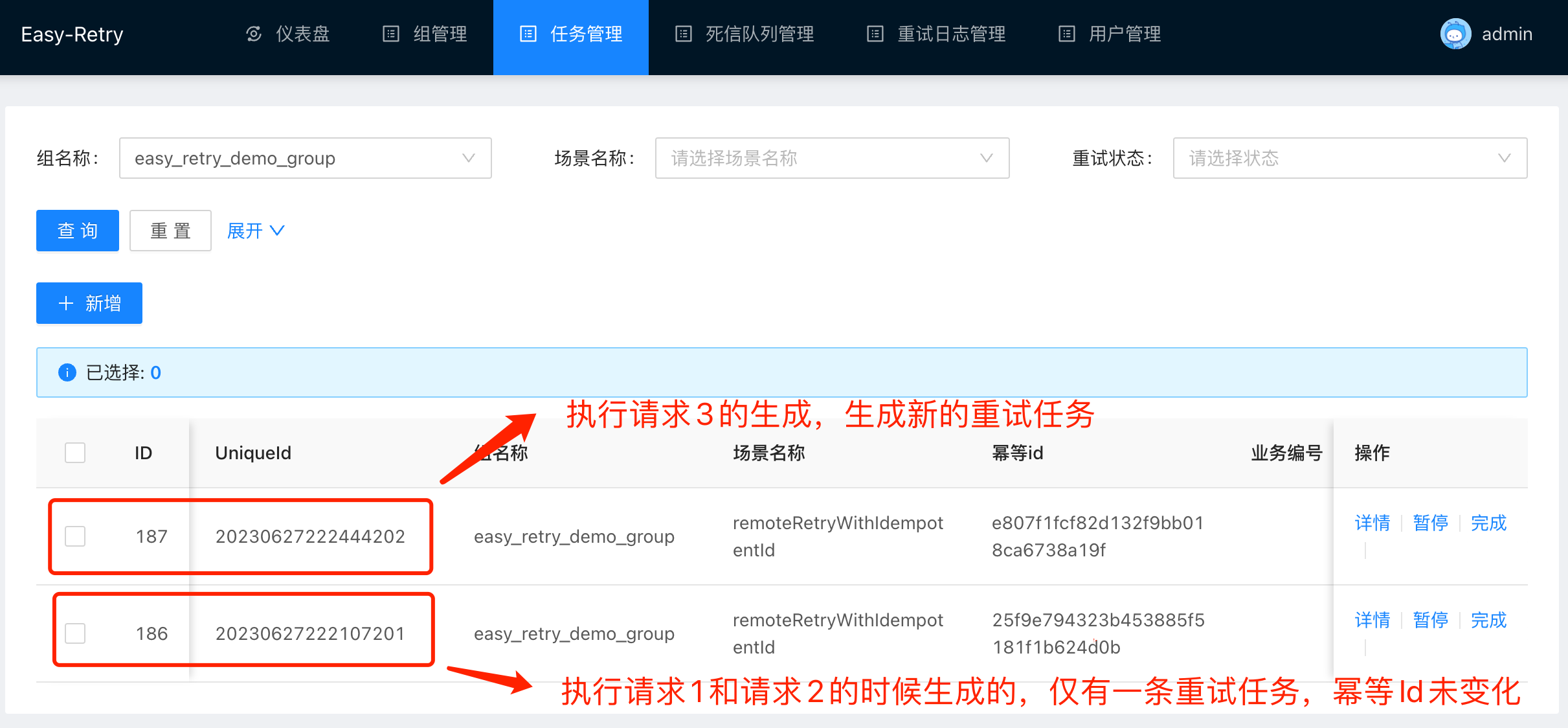
retryCompleteCallback参数允许我们自定义回调函数的逻辑。回调函数产生的过程我们在上一节中已经做过详细讲述,再次不再赘述了。接下来我们来看一下retryCompleteCallback指定的默认值SimpleRetryCompleteCallback类中实现了什么? 可以看到,默认的实现中什么都没有,也就是默认在回调的时候不会产生任何动作。
@Component
@Slf4j
public class SimpleRetryCompleteCallback implements RetryCompleteCallback {
@Override
public void doSuccessCallback(String sceneName, String executorName, Object[] params) {
}
@Override
public void doMaxRetryCallback(String sceneName, String executorName, Object[] params) {
}
}如果我们需要自行定义回调函数中的动作,那么我们可以自行实现RetryCompleteCallback类。我们还沿用上文中订单的案例。这次我们要求,当订单重试数据处理达到最大次数时,我们将失败的订单信息写入到数据库表中持久化。
@Retryable(scene = "remoteRetryWithCompleteCallback",retryStrategy = RetryType.LOCAL_REMOTE,
retryCompleteCallback = OrderCompleteCallback.class)
public boolean remoteRetryWithCompleteCallback(OrderVo orderVo){
Random random = new Random();
// 生成一个随机数,范围为0到1之间
double probability = random.nextDouble();
// 判断随机数是否小于等于0.5,即50%的概率
if (probability <= 0.5) {
// 生成的结果在50%的概率下执行这里的逻辑
throw new NullPointerException();
}
return true;
}可以看到,在上述的案例中,我们指定了当产生回调时,使用我们指定的回调方法OrderCompleteCallback,我们让程序有50%的几率抛出异常。 然后我们来写OrderCompleteCallback方法,当服务端达到最大重试次数时,我们将失败的数据插入到fail_order表中;如果服务端回调客户端重试成功了,我们就删除该订单相关的所有数据。
@Slf4j
public class OrderCompleteCallback implements RetryCompleteCallback {
@Autowired
private FailOrderBaseMapper failOrderBaseMapper;
/**
* 重试成功后的回调函数
* 参数1-场景名称
* 参数2-执行器名称
* 参数3-入参信息
*/
@Override
public void doSuccessCallback(String sceneName, String executorName, Object[] objects) {
// 重试成功后删除失败表中的数据
OrderVo orderVo = (OrderVo) objects[0];
log.info("远程重试成功,场景{},执行器{},参数信息",sceneName,executorName, JSONUtil.toJsonStr(objects));
failOrderBaseMapper.delete(
new LambdaQueryChainWrapper<>(failOrderBaseMapper)
.eq(FailOrderPo::getOrderId,orderVo.getOrderId())
);
}
/**
* 重试达到最大次数后的回调函数
* 参数1-场景名称
* 参数2-执行器名称
* 参数3-入参信息
*/
@Override
public void doMaxRetryCallback(String sceneName, String executorName, Object[] objects) {
OrderVo orderVo = (OrderVo) objects[0];
log.info("远程重试达到最大限度,场景{},执行器{},参数信息",sceneName,executorName, JSONUtil.toJsonStr(objects));
// 重试失败后插入订单失败信息
failOrderBaseMapper.insert(FailOrderPo.builder()
.orderId(orderVo.getOrderId())
.sourceId(orderVo.getSource())
.sceneName(sceneName)
.executorName(executorName)
.args(JSONUtil.toJsonStr(objects))
.build());
}
}retryMethod参数则允许我们可以来自定义重试函数的入口。
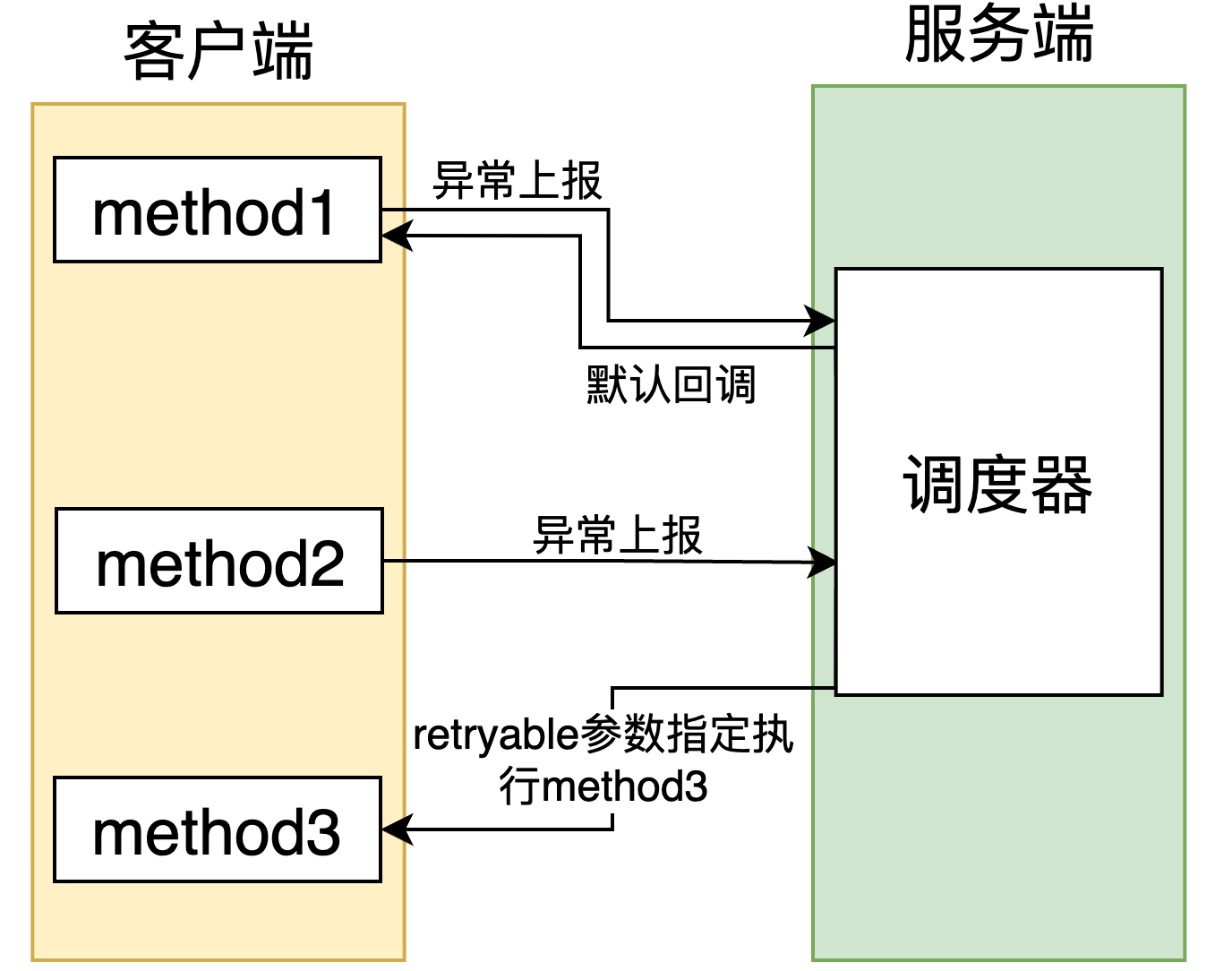
通过在retryable参数中执行方法需要执行的类,我们可以指定重试请求走到的方法。 首先我们来看一下retryable中的默认值ExecutorAnnotationMethod实现了什么?在ExecutorAnnotationMethod方法中,通过反射指定的默认重试方法就是接口的原重试方法。而我们如果要实现一个自定义的重试方法,则需要自己实现ExecutorMethod方法。
@Slf4j
public class ExecutorAnnotationMethod implements ExecutorMethod {
private RetryerInfo retryerInfo;
public ExecutorAnnotationMethod(RetryerInfo retryerInfo) {
this.retryerInfo = retryerInfo;
}
@Override
public Object doExecute(Object params) {
Class<?>[] paramTypes = retryerInfo.getMethod().getParameterTypes();
LogUtils.info(log, "执行原重试方法:[{}],参数为:[{}]", retryerInfo.getExecutorClassName(), JsonUtil.toJsonString(params));
if (paramTypes.length > 0) {
return ReflectionUtils.invokeMethod(retryerInfo.getMethod(), retryerInfo.getExecutor(), (Object[]) params);
} else {
return ReflectionUtils.invokeMethod(retryerInfo.getMethod(), retryerInfo.getExecutor());
}
}
}
public interface ExecutorMethod {
Object doExecute(Object params);
}那我们来实现一个自定义的重试方法OrderRetryMethod:
@Retryable(scene = "remoteRetryWithRetryMethod", retryStrategy = RetryType.ONLY_REMOTE,
retryMethod = OrderRetryMethod.class)
public boolean remoteRetryWithRetryMethod(OrderVo orderVo){
throw new NullPointerException();
}其中OrderRetryMethod的实现方式为:
@Component
public class OrderRetryMethod implements ExecutorMethod {
@Override
public Object doExecute(Object params) {
// 将特定类型的 Object 对象指定为 Object[]
Object[] args = (Object[]) params;
OrderVo orderVo = (OrderVo) args[0];
log.info("进入自定义的回调方法,参数信息是{}", JSONUtil.toJsonStr(orderVo));
throw new ArithmeticException();
}
}在上层调用后我们观察控制台查看输出结果:
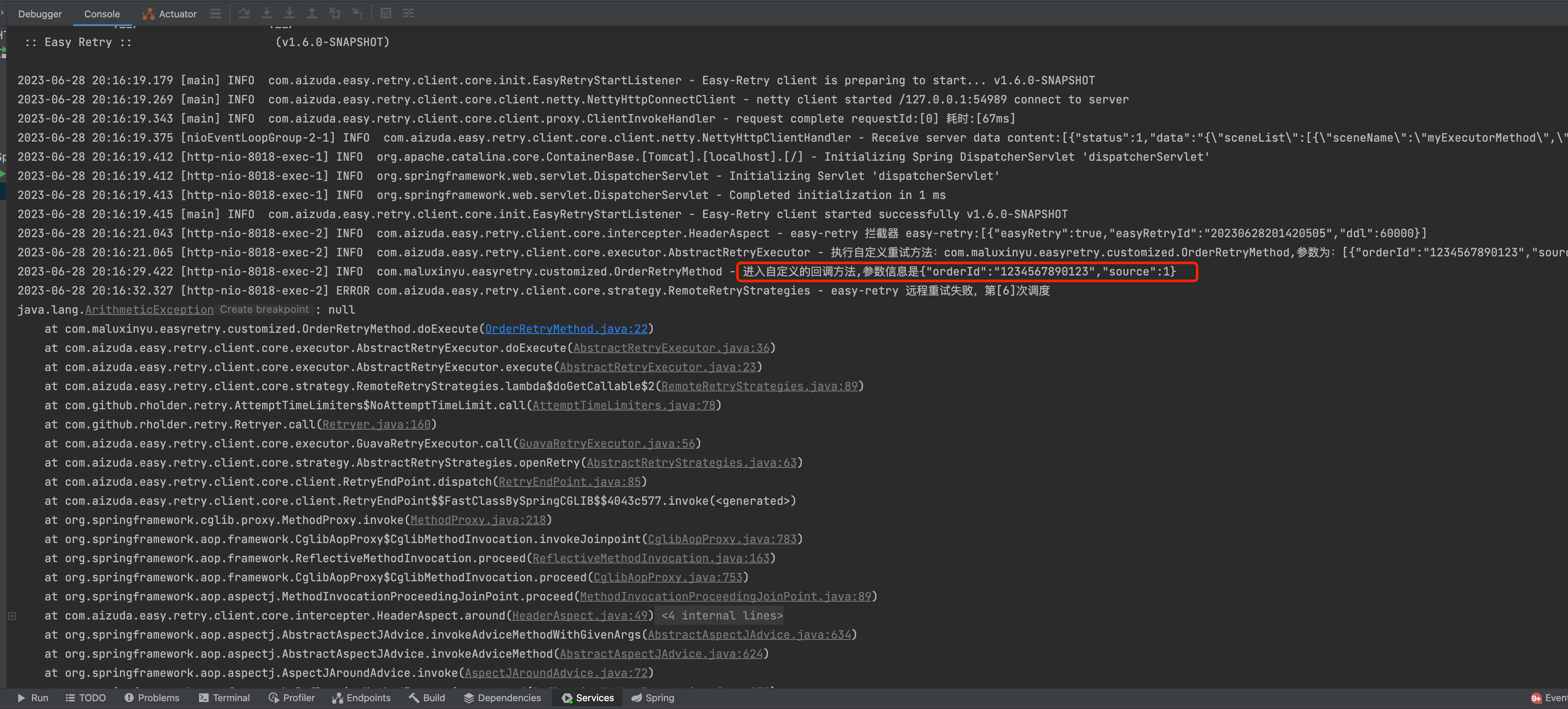
可以看到已经走进了我们的自定义方法中。
bizNo参数用于标识具有业务特点的值比如订单号、物流编号等,可以根据具体的业务场景生成。这个参数的指定主要是为了方便我们在控制台进行数据搜索。 我们给出一个简单的案例
@Retryable(scene = "remoteRetryWithBizNo",retryStrategy = RetryType.ONLY_REMOTE,bizNo = "orderVo.orderId")
public boolean remoteRetryWithBizNo(OrderVo orderVo){
throw new NullPointerException();
}随后我们通过HTTP请求调用该接口
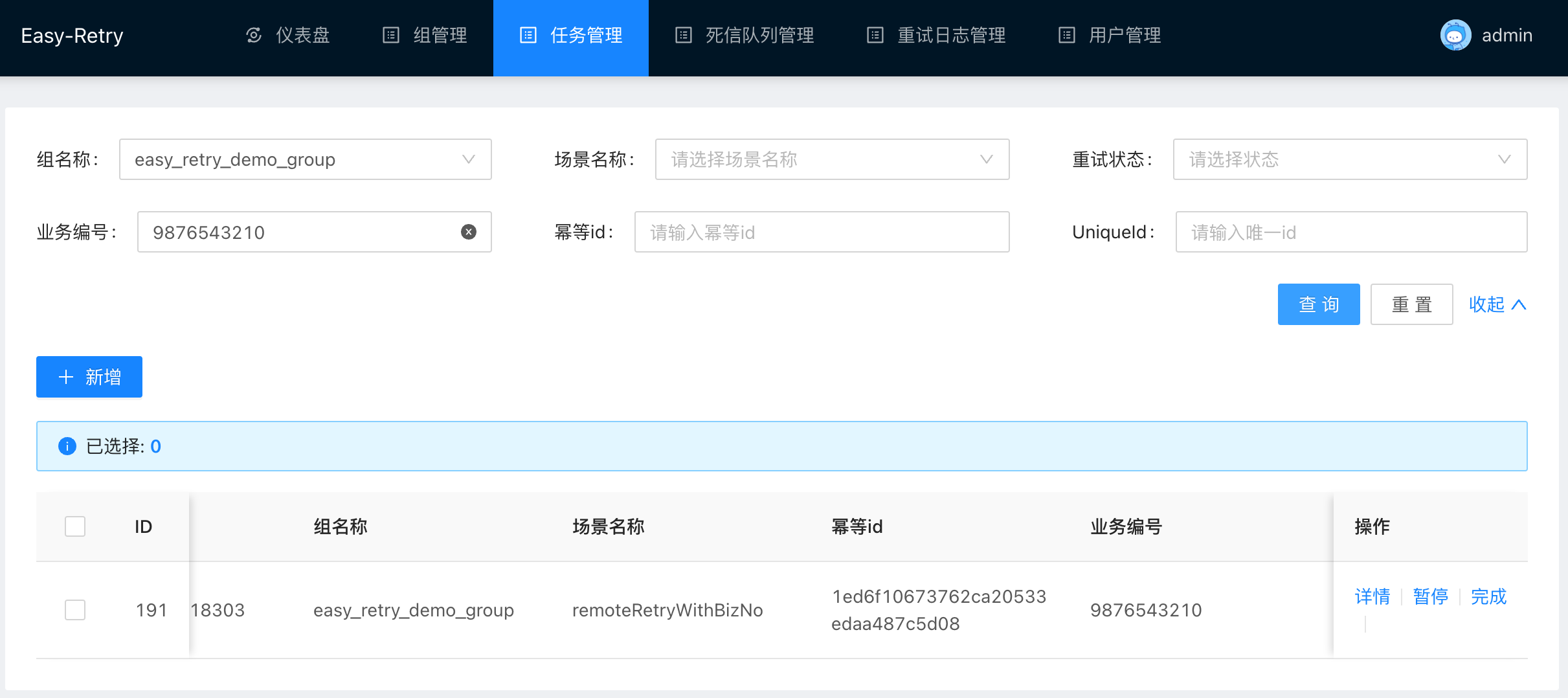
观察控制台可以看到,新注册的任务已经带上了业务编号。业务编号就是我们指定的orderId 9876543210。
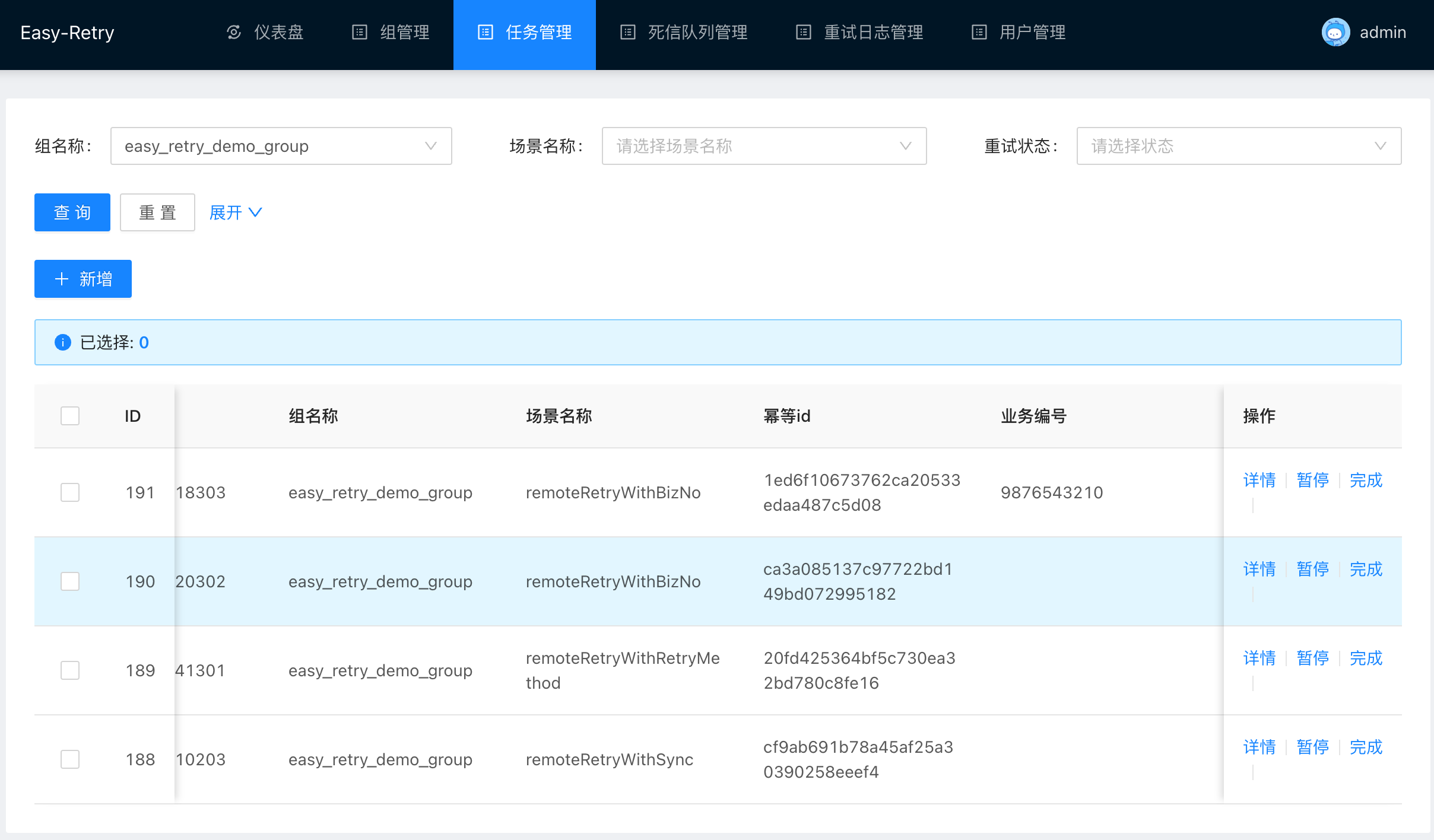
展开查询条件后我们可以看到,我们可以通过业务编号来查询重试任务,这样子当重试的任务比较多时,我们就可以通过控制台进行查询。